- Inicio
- Log TV
- Agenda
- Artículos
- Noticias
- Entrevistas
- Log Content
- Especiales
- Revistas
- Supply Chain Insights
- Brasil

Previendo y Comprendiendo la Rotación de Conductores de Camiones de Larga Distancia Usando Datos Operacionales del Conductor y Clasificadores de Machine Learning Supervisado

- machine learning supervisado
- rotación de empleados
- conductores de camiones
1. Introducción
Toda cadena de suministro en el mundo depende, en algún momento, del transporte por carretera para facilitar el movimiento de mercancías. Solo en los Estados Unidos, el transporte por carretera de mercancías es una industria de aproximadamente 800 mil millones de dólares que emplea a casi 3,5 millones de conductores profesionales (CSCMP, 2022). Sin embargo, la industria enfrenta un problema crónico y no resuelto: una rotación muy elevada de conductores de camiones, en muchos casos superior al 100% (LeMay et al., 2009; Miller et al., 2021, 2020, 2013). En los últimos años, a medida que las cadenas de suministro en todo el mundo han pasado por crisis, este problema se ha vuelto aún más evidente, especialmente para las empresas que gestionan esta rotación agitada de conductores de camiones empleados.
Este artículo adopta un enfoque único para esta importante cuestión al (1) investigar el potencial de los datos de conducción operacional recientemente disponibles para revelar patrones anteriormente no observados en la utilización de conductores de camiones; y (2) aprovechar esos patrones para predecir eventos individuales de rotación de conductores de camiones antes de que ocurran, lo que podría dar a las empresas de transporte por carretera oportunidades nuevas y valiosas para intervenir y retener a los conductores en riesgo de salida.
Nuestros datos provienen de una fuente hasta ahora inexplorada en la investigación académica sobre la rotación de conductores: los Dispositivos Electrónicos de Registro (de la sigla en inglés ELDs). En 2017, los Estados Unidos promulgaron un nuevo mandato que exigió que todos los conductores de camiones estadounidenses registraran electrónicamente sus horas de trabajo a partir de 2019. Este sistema sustituyó los registros en papel que se utilizaban anteriormente. La digitalización de estos datos creó conjuntos de datos muy grandes que permitieron nuevos conocimientos sobre las condiciones de trabajo del conductor de camión norteamericano. Entrenamos tres algoritmos de clasificación (regresión logística, bosques aleatorios y máquinas de vectores de soporte) con datos de 1.298 conductores únicos observados a lo largo de tres años para probar si, cuando se organizan según patrones semanales de utilización, estos datos recientemente disponibles podrían predecir la rotación de conductores de camiones a nivel individual.
Abordar este problema de una manera nueva añade una perspectiva única y valiosa. Como se señaló recientemente en esta publicación, la satisfacción de los conductores de camiones en el empleo es crítica para la gestión efectiva de la cadena de suministro (Khaitan et al., 2022). Los cuestionarios son la herramienta más comúnmente empleada para medir la satisfacción de los conductores de camiones en el empleo y la intención de renunciar. Sin embargo, los investigadores han notado que los cuestionarios a menudo no son prácticos y tienen costos prohibitivos en la práctica empresarial real (Khaitan et al., 2022). En segundo lugar, los investigadores han observado que los antecedentes de eventos de rotación no siempre se ajustan a los supuestos de la regresión de mínimos cuadrados y del análisis de coeficientes (Huang & Kechadi, 2013; Suzuki et al., 2009). Por estos motivos, estamos utilizando nuevos datos de trabajo operacional, que las empresas están ahora obligadas por ley a recopilar, y clasificadores de machine learning, que son capaces de explorar patrones y relaciones no lineales en estos datos, con el fin de hacer predicciones de rotación.
La sección 2 de este estudio presenta una visión general de trabajos anteriores sobre la cuestión de la rotación de conductores, casi todos ellos basados en cuestionarios (ver la Tabla 1). La sección 3 presenta los datos utilizados en este análisis. Se utilizan dos experimentos de clasificación como base, y sus resultados se presentan en las secciones 4 y 5. Las conclusiones y aplicaciones de gestión se discuten en la sección 6.
2. Trabajos relacionados
Una motivación frecuente para la investigación académica de conductores de camiones es la notoriamente alta tasa de rotación de empleados en la industria. La mayoría de los estudios publicados en la prensa académica y comercial informan que la rotación de camioneros a nivel empresarial supera el 100% anual (LeMay et al., 2009; Miller et al., 2021, 2013). Las conclusiones de trabajos anteriores sobre la identificación de los factores que llevan a los camioneros a dejar sus empleos y la contribución de este artículo al flujo de investigación sobre la rotación de camioneros se resumen a continuación.
En un análisis factorial de datos de investigaciones en la industria del transporte por carretera, Min y Lambert clasificaron 12 factores que afectan la retención de conductores de camiones y los informaron en orden decreciente de importancia. Los tres primeros incluyeron (1) remuneración competitiva; (2) antigüedad del equipo; y (3) reputación de la empresa (Min y Lambert, 2002). Esta primacía de la remuneración en la retención de conductores de camiones también ha sido confirmada en varios estudios subsiguientes, incluidos Belzer y Sedo (2018), Garver et al. (2008), Johnson et al. (2011), Keller (2002), LeMay et al. (2009), Phares y Balthrop (2022) y Williams et al. (2011). También sabemos, gracias al trabajo meticuloso de LeMay, Williams y Carver, que lo que importa para la retención de conductores de camiones varía según la edad y la experiencia del conductor. Su investigación descubrió que los conductores novatos priorizaban salarios más altos en lugar de los conductores experimentados, que priorizaban la libertad para establecer sus propios horarios (LeMay et al., 2009).
Pero otros factores también son importantes para la retención de camioneros. El tiempo fuera de casa de los conductores también ha sido consistentemente documentado como un antecedente importante de la rotación (Burks y Monaco, 2019; Corsi y Fanara, 1988; Keller, 2002; Williams et al., 2011). Sin embargo, la mayoría de los camioneros estadounidenses son pagados solo por las millas conducidas cargadas, por lo que obviamente también desean pasar algo de tiempo conduciendo en la carretera. Este equilibrio entre el tiempo libre en casa y el tiempo remunerado en carretera es donde la administración puede errar. Dos estudios anteriores nos ayudan a comprender esta difícil elección. Primero, De Croon descubrió que las semanas laborales excesivamente largas estaban correlacionadas con la insatisfacción de los conductores de camiones (De Croon et al., 2004). Burks y Monaco añadieron un corolario interesante en un estudio que identificó que la discrepancia entre las horas que un conductor planeaba conducir esa semana y las horas reales trabajadas también era un determinante importante de la satisfacción laboral (Burks y Monaco, 2019). Más específicamente, Suzuki, Patsuch y Crum identificaron una distinción importante entre los días de semana y los fines de semana en las expectativas de horas de conducción de los conductores. En su estudio, más horas de conducción por semana se correlacionaron con una mayor satisfacción laboral y, por lo tanto, una menor probabilidad de renuncia. Sin embargo, las cargas de fin de semana inferiores a 700 millas invirtieron esta relación y aumentaron la probabilidad de que algunos conductores de camiones renunciaran, probablemente porque esos viajes cortos no eran muy rentables y, por lo tanto, no valía la pena el tiempo lejos de casa (Suzuki et al., 2009).
2.1. Contribución de este artículo a la literatura
Este artículo realiza dos contribuciones únicas a la investigación sobre la rotación de conductores de camiones. Primero, en lugar de los enfoques basados más frecuentemente en cuestionarios, utilizamos nuevos datos operativos, datos de ELDs, que capturan las experiencias laborales reales de los conductores con registros electrónicos de fecha y hora. Nuestro enfoque basado en ELDs nos permite examinar los ciclos de uso del día de la semana del conductor como nuevos antecedentes para eventos de rotación de conductores. Esto es especialmente significativo en la práctica porque, como lo exige la ley, estos datos de ELDs ya están siendo recopilados por las empresas de transporte por carretera, mientras que los datos de cuestionarios pueden ser prohibitivamente costosos y difíciles de implementar (Khaitan et al., 2022). En segundo lugar, desarrollamos predictores avanzados de rotación de conductores a nivel individual utilizando regresión logística, bosques aleatorios y máquinas de vectores de soporte, técnicas que, hasta donde sabemos, no se han aplicado anteriormente en la rotación de empleados académicos ni en la literatura de sistemas de predicción especializados relacionados con conductores de camiones.
3. Datos
Los datos de ELDs fueron proporcionados por una empresa de transporte por carretera estadounidense de tamaño mediano (aproximadamente 1,500 camiones en total). Los datos se proporcionaron para cuatro períodos separados de 8 semanas, comenzando en septiembre de 2016 y terminando en agosto de 2018 (ver Tabla 2). Cada uno de los 4 conjuntos ("T1"-"T4") abarca conjuntos distintos pero superpuestos de conductores de camiones. Los conjuntos de datos se limpiaron para: (1) incluir solo conductores solitarios de larga distancia, es decir, conductores que viajan largas distancias para su trabajo y trabajan solos. Esta subcategoría de conductores es la más afectada por la escasez de conductores en los Estados Unidos (American Trucking Association, 2021). Los datos de ELDs son registros de trabajo con fecha y hora, en los cuales el conductor debe seleccionar en un menú las posibles actividades de trabajo o fuera de servicio para cada hora del día. Dado que la conducción es de interés aquí, los datos también se limpiaron para eliminar entradas de registro de trabajo donde se reportaron horas de conducción imposibles o ilegales. Los conductores de camiones estadounidenses están limitados a un máximo de 11 horas de conducción por día (FMCSA, 2022). Se excluyeron las entradas que excedían este total de 11 horas de conducción. Esta limpieza resultó en 1,298 conductores únicos de larga distancia con conjuntos de datos limpios y completos que se consideraron en este análisis.
Los ELDs requieren que los conductores asignen su tiempo a una de las cuatro categorías principales: Conduciendo, En servicio sin Conducir, Fuera de servicio y Beliche (FMCSA, 2023). Basándonos en nuestra revisión de la literatura, optamos por centrarnos en los dos estados de trabajo "Conduciendo", que es el tiempo dedicado efectivamente a conducir el camión; y "En servicio sin Conducir", que incluye, entre otras cosas, el tiempo dedicado a la espera para cargar y descargar. "Conduciendo", por supuesto, determina el salario neto que estos conductores reciben, ya que en EE.UU., los conductores de camiones son pagados por milla recorrida. "En servicio, sin conducir" incluye el tiempo de espera de los conductores para ser cargados y descargados en los remitentes y destinatarios, que los resultados de la investigación muestran que es frustrante para los conductores. Organizamos estos datos en promedios diarios de tiempo dedicado a conducir ("Conduciendo") y tiempo dedicado a trabajar pero no conduciendo ("En servicio"). Los resúmenes de estas medidas en los cuatro períodos se presentan en la Figura 1 y en la Tabla 3.
4. Metodología
4.1. Técnicas de modelado
Se aplicaron tres algoritmos clasificadores para predecir eventos de rotación de conductores basados en el promedio diario y la desviación estándar del tiempo dedicado a conducir y al estado de servicio de cada conductor. Estos clasificadores incluyen regresión logística, bosques aleatorios y máquinas de vectores de soporte. Aunque existen muchos otros algoritmos candidatos y se han aplicado en estudios de rotación, incluidos recientemente en esta revista la "General regression neural network (GRNN), Extreme Learning Machines (ELM) and Convolutional neural networks (CNN)" según Davoodi et al. (2023), así como "K-means clustering" según Huang y Kechadi (2013). Sin embargo, como señala Verbeke et al. (2011), en el modelado de la rotación, la ingeniería de características puede ser más importante que la selección del clasificador al intentar construir y comprender sistemas especializados de predicción aplicados. Por esta razón, optamos por usar tres clasificadores diferentes como una prueba robusta del poder predictivo de las características de promedio y desviación estándar del día de la semana que derivamos de los datos de los registros electrónicos de los conductores.
4.1.1. Regresión logística
El clasificador de regresión logística adapta la regresión lineal clásica al caso de variables dependientes discretas. Es decir, en lugar de estimar el valor de una variable dependiente continua (y), el modelo de regresión logística estima la probabilidad de que una observación pertenezca a un conjunto finito de clases. En esta aplicación, las dos clases posibles son los conductores que permanecieron en la empresa (codificados como '0') y los que no (codificados como '1'). Tal como se representa de manera similar en Bertsimas et al. (2016) y Huang y Kechadi (2013), la probabilidad de que una observación i pertenezca a la clase 1 está dada por la función logística de respuesta:
donde \( P(y_i = 1) \) indica la probabilidad de clasificación como 1, y \( \beta_0 \) y \( \beta \) representan la intercepción y la pendiente de la función logística de probabilidad, respectivamente.
Tabla 1
Resumen seleccionado de la literatura anterior sobre la rotación de conductores de camiones:
|
Autor(es) |
Título y revista |
Año |
Antecedentes de la renuncia identificados |
Método |
|
|
Min e Lambert |
Truck driver shortage revisited - Transportation journal |
2002 |
Condiciones de trabajo, desarrollo de carrera, factores monetarios |
|
|
|
Keller |
Driver relationships with customers and driver turnover - Journal of business logistics |
2002 |
Pago, tiempo en casa, relación con el expedidor, relaciones con clientes |
|
|
|
Garver e Williams |
Employing latent class regression analysis to examine logistics theory: An application of truck driver retention - Journal of business logistics |
2008 |
Pago, relación con el expedidor, relación con la gerencia |
Análisis de cuestionario |
|
|
Lemay, Willams, Carver |
A Triadic view of truck driver satisfaction - Journal of transportation management |
2009 |
Conductores mayores quieren más libertad, conductores jóvenes quieren pagos más altos |
Análisis de cuestionario |
|
|
Suzuki, Crum, e Pautsch |
Predicting truck driver turnover - Transportation research part E |
2009 |
Horas conduciendo, datos demográficos del conductor, relaciones con expedidores |
|
|
|
Johnson, Bristo, McClure e Schneider |
Determinants of job satisfaction among long-distance truck drivers - International journal of management |
2011 |
Tiempo fuera de casa, pago, falta de respeto de los embarcadores |
Entrevistas |
|
|
Williams, Garver e Taylor |
Understanding truck driver need-based segments: Creating a strategy for retention - Journal of business logistics |
2011 |
Pago, seguridad personal, tiempo en casa, equipo, avance en la carrera, carga de trabajo, relación con el expedidor |
Análisis de cuestionario |
|
|
Lemay e Williams |
The causes of truck driver intent-to-quit: A best-fit regression - Int’l journal of commerce and management |
2013 |
Responsividad de los expedidores |
Cuestionario |
|
|
Prockl, Teller, Kotzan e Angell |
Antecedents of truck drivers’ job satisfaction and retention proneness - Journal of business logistics |
2017 |
El apoyo no financiero de los empleadores importa más que el apoyo financiero |
Análisis de cuestionario |
|
|
Belzer e Sedo |
Why do long-distance truck drivers work extremely long hours? - The economic and labor relations review |
2018 |
Los conductores quieren conducir más horas hasta alcanzar una meta de ingresos |
Análisis de cuestionario |
|
|
Burks e Monaco |
Is the US labor market for truck drivers broken? - Monthly labor review |
2019 |
La diferencia entre las horas de trabajo esperadas y las horas reales trabajadas |
Análisis de cuestionario del gobierno |
|
|
Phares e Balthrop |
Investigating the role of competing wage opportunities in truck driver occupational choice - Journal of business Logistics |
2022 |
Aumentos de salario ayudan en la retención, pero deben superar los aumentos concurrentes en ocupaciones industriales competidoras |
Análisis econométrica |
Tabla 2
Períodos de tiempo y observaciones de los datos no tratados:
|
Período |
Experimento |
Fechas |
Conductores únicos |
Conductores mantenidos |
Conductores rotados |
|
T1 |
E1 |
18/09/16 a 12/11/16 |
786 |
- |
281 (36%) |
|
T2 |
E2 |
19/02/17 a 15/04/17 |
763 |
482 (63%) |
- |
|
T3 |
E3 |
04/03/18 a 28/04/18 |
512 |
- |
158 (31%) |
|
T4 |
E4 |
24/06/18 a 18/08/18 |
556 |
398 (72%) |
- |
Tabla 3
Estadísticas resumidas de horas de conducción para todos los períodos de tiempo.
|
Estadística |
Lunes |
Martes |
Miércoles |
Jueves |
Viernes |
Sábados |
Domingos |
|
Promedio de horas de conducción Desviación estándar |
6.25 1.71 |
7.06 1.44 |
7.28 1.39 |
7.23 1.36 |
6.95 1.42 |
6.73 1.67 |
6.26 1.98 |
|
Promedio de horas en servicio Desviación estándar |
1.43 1.61 |
1.47 1.59 |
1.43 1.53 |
1.14 1.21 |
1.16 1.33 |
1.09 1.70 |
1.04 1.76 |
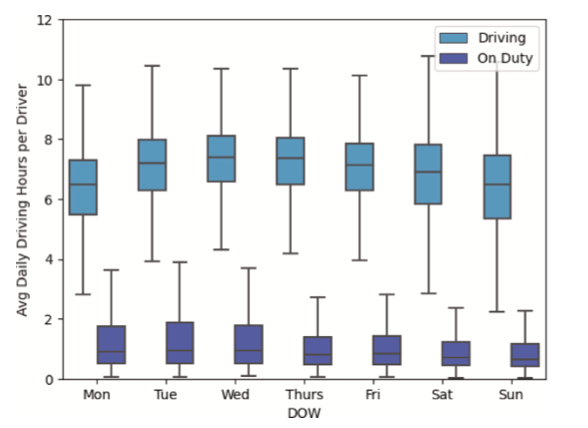
Fig. 1. Resumen del promedio de horas conduciendo por día de la semana en todos los períodos de tiempo.
4.1.2. Bosques aleatorios
El clasificador de bosque aleatorio es un clasificador de conjunto basado en árboles (Breiman, 2001; Cutler et al., 2012). Se basa en la intuición de los clasificadores de árboles de decisión, aplicando un gran número de árboles de decisión, cada uno entrenado en un subconjunto de los datos disponibles. El clasificador de bosque aleatorio recoge el voto de cada árbol de decisión para la clasificación correcta de una observación, basándose en el subconjunto de variables independientes en el que se entrenó el árbol individual (Bertsimas et al., 2016). Los votos se computan a partir de la "selva" de árboles de decisión entrenados y se realiza una clasificación. A continuación se presenta un breve pseudocódigo para el clasificador de bosque aleatorio, basado en Hastie et al. (2009).
Algoritmo 1: Bosque Aleatorio para Clasificación
1. Para \( b = 1 \) hasta \( B \):
(a) Extraer una muestra bootstrap \( Z^* \) de tamaño \( N \) a partir de los datos de entrenamiento.
(b) Crecer un árbol de bosque aleatorio \( T \) utilizando los datos de bootstrap, repitiendo los siguientes pasos para cada nodo terminal del árbol, hasta que se alcance el tamaño mínimo del nodo \( n_{\text{min}} \).
i. Seleccionar \( m \) variables aleatoriamente de \( p \) variables.
ii. Elegir el mejor punto de división variable entre las \( m \).
iii. Dividir el nodo en dos nodos hijos.
2. Producir el conjunto de árboles.
Para hacer una predicción en un nuevo punto \( x \):
Clasificación: Sea la predicción de clase del b-ésimo árbol del bosque. Entonces
Adaptado de Hastie et al. 2009, p. 588.
4.1.3. Máquinas de vectores de soporte
El clasificador de vectores de soporte asigna predicciones de clase definiendo un hiperplano multidimensional que separa observaciones de entrenamiento etiquetadas en un espacio de características n-dimensional. El clasificador esencialmente encuentra los límites o bordes del recurso de un hiperplano candidato que minimiza los errores de clasificación en el conjunto de entrenamiento. Esto puede formularse como un problema de optimización convexa, presentado por Hastie et al. (2009) en su forma muy general:
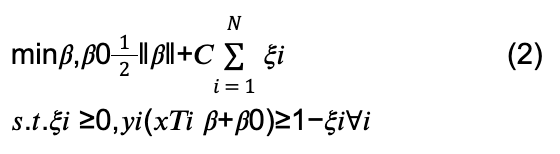
donde ???? es un vector unitario ‖????‖ = 1; C representa un parámetro de costo (esencialmente ∞ en el caso de ser linealmente separable); y ????1 , ????2 , ... , ???????? representan variables de holgura.
4.2. Modelando flujo de trabajo y procesamiento de datos
Los datos fueron proporcionados al equipo de investigación en cuatro períodos distintos de ocho semanas a lo largo de dos años. Es importante destacar que la recopilación de datos fue realizada por la empresa de manera independiente de nuestra influencia o proyecto experimental. Exploramos la estructura única del conjunto de datos para llevar a cabo dos experimentos naturales. El Experimento 1 prueba predicciones para los conductores que aparecen en T1, pero no aparecen tres meses después en T2. El Experimento 1 incluyó un total de 782 conductores, de los cuales 281 renunciaron (36%). El Experimento 2 prueba predicciones para los conductores que aparecen en T3, pero no aparecen tres meses después en T4. El Experimento 2 incluyó 512 conductores, de los cuales 158 renunciaron antes de T4 (31%). El experimento T3 a T4 fue descartado debido al intervalo de tiempo mucho más largo entre los períodos (11 meses).
Cada algoritmo clasificador fue entrenado, ajustado y probado para cada experimento. Primero entrenamos y ajustamos los algoritmos clasificadores en un conjunto de entrenamiento/ajuste que comprendía el 60% de los datos disponibles de ese experimento. Usando validación cruzada de 5 veces, ajustamos cada algoritmo clasificador para el conjunto de entrenamiento de cada experimento. Luego probamos cada algoritmo clasificador hiperajustado en el 40% restante de los datos disponibles de cada experimento. Este enfoque se presenta en la Figura 2. Los análisis fueron codificados en el lenguaje de programación Python y se utilizaron la biblioteca de aprendizaje automático scikit-learn (Pedregosa et al., 2011) y el paquete de hiperajuste Optuna (Akiba et al., 2019).
4.2.1. Rendimiento del modelo
Se informan tres medidas de rendimiento del modelo: Área Bajo la Curva (AUC), precisión y recall, así como una representación gráfica, la Curva Característica de Operación del Receptor (ROC, por sus siglas en inglés).
Siguiendo la presentación en Huang y Kechadi (2013), el rendimiento de los algoritmos clasificadores se puede entender mediante matrices de confusión. La matriz de confusión muestra recuentos de clasificaciones correctas e incorrectas por clase. Consulte la Tabla 4.
Tabla 4
Ejemplo de matriz de confusión para los experimentos 1 y 2:
|
Predicción |
|||
|
Rotacionado |
No rotacionado |
||
|
Real |
Rotacionado No rotacionado |
????11 ????21 |
????12 ????22 |
4.2.2. Precisión y sensibilidad
La precisión se refiere al porcentaje de todas las clasificaciones que fueron correctas. En el contexto de este estudio, esto significaría el porcentaje de todos los conductores que fueron correctamente clasificados como habiendo sido despedidos o no. En el contexto de la Tabla 4, esto se calcularía como:
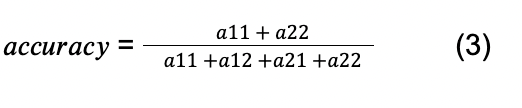
La sensibilidad es una medida de la probabilidad de predecir una clasificación positiva, dado que tal clasificación es realmente verdadera. En el contexto de este estudio, esto significa la probabilidad de prever un evento de rotación de conductores, dado que el conductor realmente rotó. Verbeke et al. destacan que, en el contexto de la predicción de rotación, los costos asociados con falsos positivos y falsos negativos no son iguales. Es más costoso perder un verdadero positivo y perder la oportunidad de intervenir. Por esta razón, la sensibilidad (a veces llamada 'recall') es una medida de rendimiento especialmente relevante (Verbeke et al., 2011). Dada la notación en la Tabla 2, esto se calcularía como:
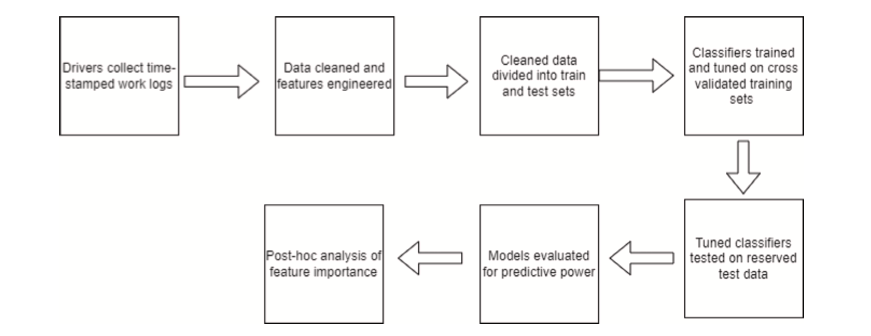
Fig. 2. Diagrama esquemático del flujo de trabajo para la recolección de datos, ingeniería de características, calibración y análisis de modelo.
4.2.3. Curva Característica del Operador del Receptor (ROC)
Las curvas características del operador del receptor (ROC), como las mostradas en la Fig. 5, resumen el desempeño de un clasificador. Con la tasa de verdaderos positivos en el eje OY y la tasa de falsos positivos en el eje OX, una estimación completamente aleatoria tendría una probabilidad de 50/50 de clasificación correcta (Bertsimas et al., 2016; Bradley, 1997). En las curvas ROC de las Figs. 3 y 4, trazamos esa línea de paseo aleatorio 50/50 en trazos grises. En este sentido, un clasificador que se sitúa por encima de la línea de paseo aleatorio en la curva ROC predice mejor que una estimación aleatoria.
4.2.4. Área bajo la curva (AUC)
La información presentada en una curva ROC puede resumirse con una estadística de Área Bajo la Curva (AUC). Como su nombre indica, AUC resume el área bajo la línea ROC convexa. Puntuaciones más altas en la AUC implican que el clasificador es más capaz de distinguir entre clases. Formalmente, la AUC se puede calcular como:
donde ????0 es la suma de las observaciones de la clase 0, ????0 es el número de observaciones que pertenecen a la clase 0 y ????1 es el número de observaciones que pertenecen a la clase 1 (rotatividad). Esta explicación resume tratamientos similares en Bradley (1997) y Huang y Kechadi (2013).
Tabla 5
Desempeño único del clasificador en datos de prueba en los experimentos 1 y 2.
|
Experimento |
Clasificador |
AUC |
Precisión |
Sensibilidad |
|
E1 E1 E1 |
Regresión logística
Máquina de vectores de soporte |
0.57 0.63 0.62 |
0.64 0.67 0.67 |
0.50 0.39 0.36 |
|
E2 E2 E2 |
Regresión logística Bosque aleatorio
Máquina de vectores de soporte |
0.56 0.63 0.61 |
0.68 0.69 0.69 |
0.56 0.52 0.50 |
5. Resultados
6. Resultados y discusión
6.1. Rendimiento de los clasificadores
Los resultados de los experimentos de rotación se muestran en la Tabla 5. Esta tabla reporta el AUC, precisión y sensibilidad para una instancia de cada uno de los tres clasificadores. Las Figuras 3 y 4 muestran de manera similar las curvas ROC y las puntuaciones de AUC para estos experimentos.
En ambos experimentos, estos clasificadores mostraron un poder predictivo imperfecto, pero superior al de una estimación aleatoria (la línea de 'paseo aleatorio' en las Figuras 3 y 4). Las puntuaciones de precisión se acercan al 70% en los mejores casos, lo que significa que, en la mayoría de los casos, los clasificadores de aprendizaje automático entrenados en datos de ELDs hacen predicciones correctas sobre la rotación. Sin embargo, las puntuaciones de sensibilidad son notablemente bajas para todos los algoritmos en ambos experimentos. Como se muestra en la Tabla 5, aproximadamente la mitad de los conductores que realmente rotaron fueron clasificados incorrectamente por nuestros algoritmos predictivos.
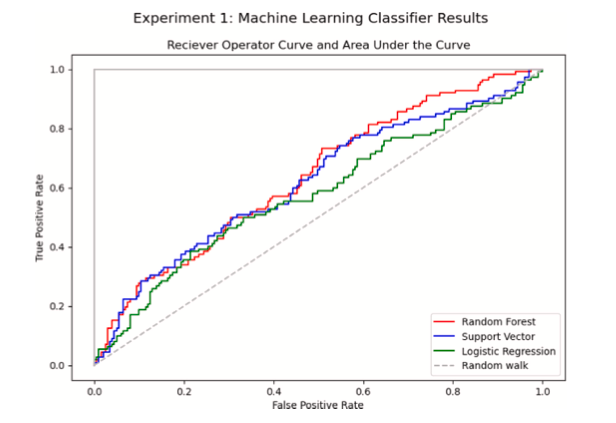
Fig. 3. Curva ROC para el Experimento 1.
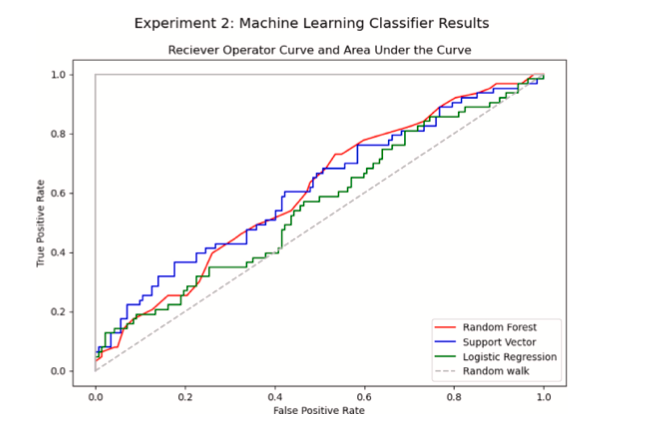
Fig. 4. Curva ROC para el Experimento 2.
6.2. Robustez de los resultados de precisión
Usando validación cruzada de 5 veces, también probamos la robustez de estos hallazgos. Estos resultados son generalmente consistentes en la replicación. Los resultados de precisión se agrupan ordenadamente entre el 60 y el 70% entre clasificadores y experimentos. Los clasificadores de bosques aleatorios y máquinas de vectores de soporte mostraron potencial para una variación positiva alcanzando entre el 70 y el 80%. Los resultados de sensibilidad muestran resultados igualmente consistentes, con puntuaciones agrupadas en torno al 50 y 60% entre algoritmos y experimentos. Los resultados de precisión y robustez de la validación cruzada de los tres clasificadores se compararon usando pruebas de Friedman, de acuerdo con la orientación de Demšar (2006). En cada comparación de precisión y robustez experimental, no se pudo rechazar la hipótesis nula de tendencia central no paramétrica equivalente. Los tres clasificadores parecen haber tenido un rendimiento igualmente bueno. Estos resultados se muestran para cada clasificador y cada experimento en las Figuras 5 y 6.
6.3. Importancia del recurso post hoc
Para obtener más información sobre lo que los datos de ELDs preparados pueden decirnos sobre la rotación de conductores de camiones de larga distancia, realizamos un análisis post hoc de la importancia del recurso. En este caso, esto significa comprender el papel que cada característica del día de la semana (promedio de horas y desviación estándar de horas) proyectada a partir de los datos brutos de los ELDs desempeñó en la predicción de la rotación a nivel de conductor. Esto es similar al enfoque en Davoodi et al. (2023). Sin embargo, en nuestro contexto, optamos por usar valores de Shapley Additive Explanations (SHAP) al comparar la importancia del recurso. Los valores SHAP representan la contribución aditiva única de cada recurso para la predicción del modelo (Baptista et al., 2022; Lee et al., 2023; Lundberg y Lee, 2017). En las Figuras 7 y 8 mostramos el valor SHAP de cada recurso en cada experimento, para cada uno de los tres clasificadores en orden descendente de importancia por experimento y por clasificador.
Varios patrones resultan de la observación de las Figuras 7 y 8. Primero, al observar los principales predictores, los recursos basados en el tiempo de conducción generalmente tienen una clasificación más alta que los recursos basados en el tiempo de espera. Al considerar los 10 valores SHAP más altos en recursos y experimentos, la conducción domina en 4 de los 6 casos de clasificador por experimento. También podemos observar que los recursos basados en el promedio y en la desviación estándar son importantes para hacer predicciones. En 4 de los 6 experimentos con clasificadores, los 10 principales recursos incluyeron una combinación uniforme de ambos tipos de medidas. Finalmente, los recursos basados en días de la semana (lunes, martes, miércoles y jueves) dominan sobre los recursos basados en fines de semana (sábado y domingo) en todas las instancias del clasificador por experimento. Al final, la cantidad y consistencia de las horas de conducción durante la semana laboral parecen ser las mayores responsables del poder predictivo de nuestro modelo.
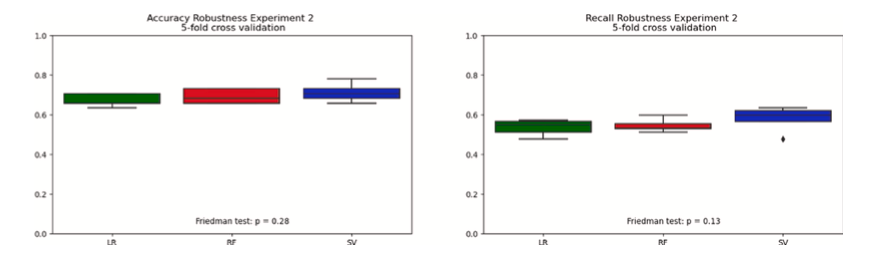
Fig. 5. Precisión en el Experimento 1.
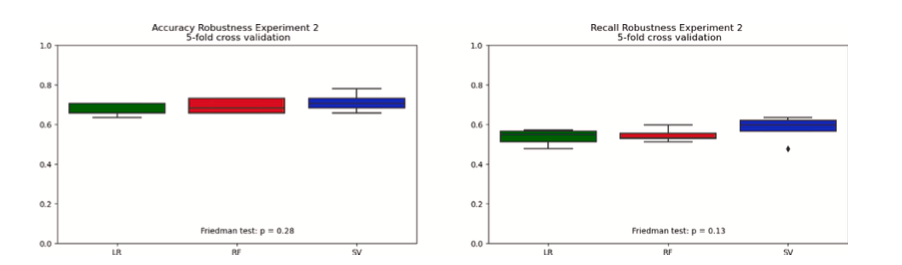
Fig. 6. Precisión en el Experimento 2.
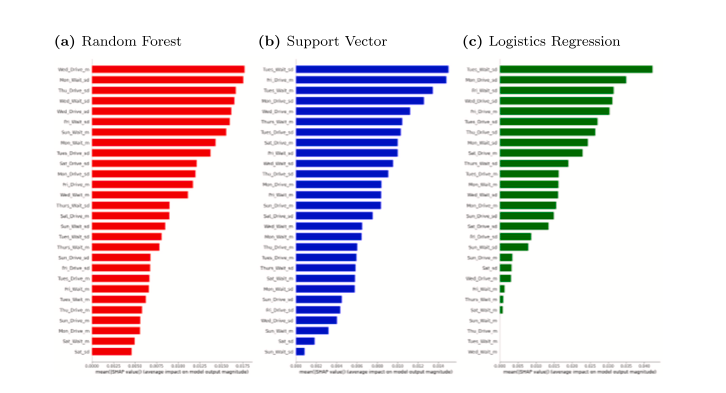
Fig. 7. Valores SHAP en el Experimento 1.
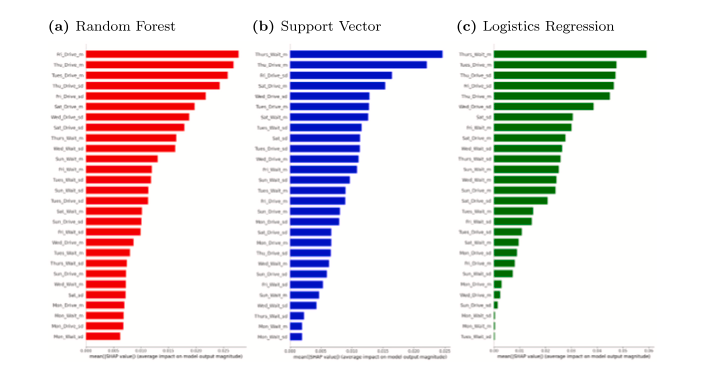
Fig. 8. Valores SHAP en el Experimento 2.
8. Conclusiones y trabajos futuros
Este trabajo explora el potencial de una nueva fuente de datos, los Dispositivos de Registro Electrónico, para prever eventos de rotación de conductores. Para investigar este potencial, preparamos datos brutos de ELDs proporcionados por una empresa estadounidense de transporte por carretera de mediano tamaño para aproximadamente 1,200 conductores en dos experimentos diferentes. Organizamos los recursos basados en el tiempo dedicado a conducir y el tiempo de espera por día de la semana. Consideramos el promedio y las desviaciones estándar de ambas medidas. Aplicamos tres clasificadores a los datos preparados: regresión logística, bosques aleatorios y máquinas de vectores de soporte. Estos modelos mostraron una precisión del 60 al 70% y una sensibilidad del 50 al 60% en los dos experimentos y en los tres clasificadores. De hecho, los datos de ELD parecen tener un potencial anteriormente no reconocido para prever la rotación individual de conductores de camiones cuando se utilizan de esta manera con clasificadores de machine learning supervisados. Dado que la capacidad saludable del transporte por carretera es fundamental para el funcionamiento de las cadenas de suministro modernas, proponemos que estos resultados ofrecen nuevas herramientas técnicas, así como insights para mejorar los problemas globales de retención de camioneros en beneficio de las cadenas de suministro en todo el mundo.
Trabajos futuros podrían considerar la expansión de estos insights en otros contextos. Los datos disponibles para nuestro equipo de investigación fueron recolectados únicamente de conductores estadounidenses de camiones de larga distancia contratados. Aunque estos conductores representan la gran mayoría de la escasez de camioneros en Estados Unidos (Association, 2022), no representan a toda la comunidad global de camioneros. Esperamos que estos hallazgos sean probados en cuanto a su generalización también en otros contextos.
REFERENCIAS
Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. (2019). Optuna: A next- generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 2623–2631).
American Trucking Association, A. (2021). Driver short- age update 2021: Tech. rep., American Trucking Association, https://www.trucking.org.
Association, A. T. (2022). American trucking association driver short-age report: Tech. rep., American Trucking Association.
Baptista, M. L., Goebel, K., & Henriques, E. M. (2022). Relation between prognostics predictor evaluation metrics and local interpretability SHAP values. Artificial Intelligence, 306, Article 103667.
Belzer, M. H., & Sedo, S. A. (2018). Why do long distance truck drivers work extremely long hours? The Economic and Labour Relations Review, 29(1), 59–79.
Bertsimas, D., Allison, K., & Pulleyblank, W. R. (2016). The analytics edge. Dynamic Ideas LLC Charlestown, MA.
Bradley, A. P. (1997). The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition, 30(7), 1145–1159.
Breiman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Burks, S. V., & Monaco, K. (2019). Is the U.S. labor market for truck drivers broken.
Monthly Labor Review, 1–23.
Corsi, T. M., & Fanara, P., Jr. (1988). Driver management policies and motor carier
safety. Logistics and Transportation Review, 24(2), 153–163.
CSCMP (2022). CSCMP’s annual state of logistics report: Tech. rep., Council of Supply
Chain Management Professionals.
Cutler, A., Cutler, D. R., & Stevens, J. R. (2012). Random forests. In C. Zhang, & Y. Ma (Eds.), Ensemble machine learning: methods and applications. Springer.
Davoodi, S., Thanh, H. V., Wood, D. A., Mehrad, M., Rukavishnikov, V. S., & Dai, Z. (2023). Machine-learning predictions of solubility and residual trapping indexes of carbon dioxide from global geological storage sites. Expert Systems with Applications, 222, Article 119796.
De Croon, E. M., Sluiter, J. K., Blonk, R. W., Broersen, J. P., & Frings-Dresen, M. H.
(2004). Stressful work, psychological job strain, and turnover: a 2-year prospective
cohort study of truck drivers. Journal of Applied Psychology, 89(3), 442.
Demšar, J. (2006). Statistical comparisons of classifiers over multiple data sets. The
Journal of Machine Learning Research, 7, 1–30.
FMCSA (2022). Summary of hours of service regulations. http://www.fmcsa.dot.gov/
regulations/hours- service/summary- hours- service- regulations.
FMCSA (2023). Federal motor carrier administration - electronic logging de- vices. from
https://eld.fmcsa.dot.gov/, Retrieved May 12, 2023.
Garver, M. S., Williams, Z., & Taylor, G. S. (2008). Employing latent class regression analysis to examine logistics theory: an application of truck driver retention. Journal of Business Logistics, 29(2), 233–257.
Hastie, T., Tibshirani, R., Friedman, J. H., & Friedman, J. H. (2009). The elements of statistical learning: data mining, inference, and prediction, Vol. 2. Springer.
Huang, Y., & Kechadi, T. (2013). An effective hybrid learning system for telecommunication churn prediction. Expert Systems with Applications, 40(14), 5635–5647.
Johnson, J. C., Bristow, D. N., McClure, D. J., & Schneider, K. C. (2011). Determinants of job satisfaction among long-distance truck drivers: An interview study in the United States. International Journal of Management, 28(1), 203.
Keller, S. B. (2002). Driver relationships with customers and driver turnover: key mediating variables affecting driver performance in the field. Journal of Business Logistics, 23(1), 39–64.
Khaitan, A., Mehlawat, M. K., Gupta, P., & Pedrycz, W. (2022). Socially aware fuzzy vehicle routing problem: A topic modeling based approach for driver well-being. Expert Systems with Applications, 205, Article 117655.
Lee, Y.-G., Oh, J.-Y., Kim, D., & Kim, G. (2023). SHAP value-based feature impor- tance analysis for short-term load forecasting. Journal of Electrical Engineering & Technology, 18(1), 579–588.
LeMay, S. A., Williams, Z., & Carver, M. (2009). A triadicic view of truck driver satisfaction. Journal of Transportation Management, 21(2), 1–15.
Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in neural information processing systems, Vol. 30. Curran Associates, Inc., https://proceedings.neurips.cc/paper_files/ paper/2017/file/8a20a8621978632d76c43dfd28b67767- Paper.pdf.
Miller, J. W., Bolumole, Y., & Muir, W. A. (2021). Exploring longitudinal industry-level large truckload driver turnover. Journal of Business Logistics, 42(4), 428–450. Miller, J. W., Muir, W. A., Bolumole, Y., & Griffis, S. E. (2020). The effect of truckload driver turnover on truckload freight pricing. Journal of Business Logistics, 41(4), 294–309.
Miller, J. W., Saldanha, J. P., Hunt, C. S., & Mello, J. E. (2013). Combining formal controls to improve firm performance. Journal of Business Logistics, 34(4), 301–318. Min, H., & Lambert, T. (2002). Truck driver shortage revisited. Transportation Journal, 5–16.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825–2830.
Phares, J., & Balthrop, A. (2022). Investigating the role of competing wage oppor- tunities in truck driver occupational choice. Journal of Business Logistics, 43(2), 265–289.
Suzuki, Y., Crum, M. R., & Pautsch, G. R. (2009). Predicting truck driver turnover. Transportation Research Part E: Logistics and Transportation Review, 45(4), 538–550. Verbeke, W., Martens, D., Mues, C., & Baesens, B. (2011). Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Systems with Applications, 38(3), 2354–2364.
Williams, Z., Garver, M. S., & Stephen Taylor, G. (2011). Understanding truck driver need-based segments: creating a strategy for retention. Journal of Business Logistics, 32(2), 194–208