- Inicio
- Log TV
- Agenda
- Artículos
- Noticias
- Entrevistas
- Log Content
- Especiales
- Revistas
- Supply Chain Insights
- Brasil

El Futuro Ya Llegó: IA y Machine Learning en Logística y Supply Chain

Recientemente, inicié una conferencia sobre la aplicación de Inteligencia Artificial (IA) en Logística y Supply Chain con una pregunta intrigante: "¿Cuántos de ustedes han utilizado IA en su lugar de trabajo?" La respuesta fue modesta, con solo cinco personas levantando la mano. Profundizando en la cuestión, pregunté: "¿Y cuántos de ustedes han hecho uso de IA esta mañana?" Para mi sorpresa, solo dos manos se levantaron, incluida la mía. Este momento fue crucial para resaltar una reflexión importante: aunque muchas veces no lo percibimos, la IA forma parte integral de nuestra vida cotidiana. Ya sea al elegir una película en Netflix, escuchar una nueva lista de reproducción en Spotify, solicitar un coche por Uber o incluso interactuar con Alexa, constantemente nos beneficiamos de aplicaciones impulsadas por IA. Incluso, el simple acto de revisar nuestros correos electrónicos está permeado por la presencia del Aprendizaje Automático (Machine Learning - ML), con algoritmos dedicados a separar mensajes no deseados y spam del resto de nuestra correspondencia. El objetivo de esta observación era evidenciar que, independientemente de nuestra percepción consciente, el uso de la IA es una realidad incontestable y presente en nuestras vidas diarias.
La Inteligencia Artificial (IA) puede ser caracterizada como la capacidad de las máquinas para ejecutar tareas que, tradicionalmente, requerirían la cognición humana, como percibir, razonar, aprender y resolver problemas. Dentro de este amplio espectro, el aprendizaje automático (Machine Learning - ML) emerge como un pilar central, situándose junto a otras áreas significativas como la robótica, el procesamiento del lenguaje natural (PLN), la visión por computadora y el reconocimiento de voz. Es importante destacar que el ML se ha establecido como el subcampo más influyente de la IA, empleando datos históricos para desarrollar modelos capaces de anticipar resultados futuros o comportamientos de datos nuevos, representando una frontera avanzada en el campo de la inteligencia artificial.

El descubrimiento de que el 90% de los datos globales fueron creados en los últimos dos años fue una revelación asombrosa para mí. Esta estadística arroja luz sobre la increíble explosión de información que estamos experimentando y destaca claramente el papel crucial del Machine Learning en este contexto. ML se nutre y evoluciona gracias a estos inmensos volúmenes de datos, explorándolos para aprender patrones, hacer predicciones y mejorar decisiones. Este escenario refuerza la gran importancia de desarrollar sistemas de inteligencia artificial sofisticados que puedan no solo gestionar, sino también comprender y extraer valor de esta vastedad de información con eficacia.
Método de Machine Learning
El aprendizaje automático es una disciplina fascinante que se apoya en la utilización de datos, modelos probabilísticos y algoritmos para descubrir patrones y hacer predicciones. El proceso inicia con la identificación clara del problema a ser resuelto, seguida por la etapa crucial de limpieza de datos, donde las inconsistencias y ruidos son eliminados para garantizar la calidad del análisis. Una vez preparados, los datos son utilizados en la implementación del modelo de aprendizaje automático, que es cuidadosamente elegido y configurado de acuerdo con el desafío en cuestión.
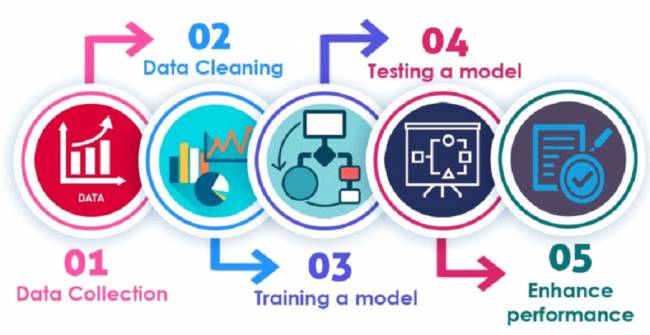
Después de la implementación, el modelo es sometido a un riguroso proceso de entrenamiento y prueba, permitiéndole aprender con los datos proporcionados y evaluar su eficacia. La evaluación es una fase crítica donde el desempeño del modelo se mide a través de métricas específicas, asegurando que cumpla con los criterios de éxito establecidos. Con la aprobación en todas las etapas anteriores, el modelo es entonces implantado para aplicación práctica, donde comienza a resolver el problema identificado en el mundo real.
Sin embargo, el trabajo no termina con la implantación. La actualización continua del modelo es esencial para mantener su relevancia y eficacia, ajustándolo conforme se reciban nuevos datos y retroalimentaciones. Esto garantiza que el modelo permanezca eficiente frente a cambios en los patrones de datos o en las condiciones del problema.
Los métodos de aprendizaje automático se dividen en tres grandes familias, cada una con sus peculiaridades y aplicaciones. Los métodos de aprendizaje supervisado utilizan datos de entrenamiento etiquetados para hacer predicciones sobre nuevos datos, siendo ideales para tareas como previsión de demanda, clasificación de imágenes, detección de fraude, identificación de causas de retrasos/fallas y diagnósticos médicos. Los métodos de aprendizaje no supervisado buscan patrones en conjuntos de datos sin etiquetas predefinidas, útiles para segmentación de clientes/proveedores y recomendaciones de productos. Por último, el aprendizaje por refuerzo se centra en la optimización de decisiones y en la adquisición de habilidades mediante recompensas, pavimentando el camino para avances significativos en áreas que exigen adaptación y mejora continua.
Ejemplo de Uso de ML en Transporte
Estudiantes de la FEI ayudaron a un minorista a identificar las causas de retrasos en transferencias de mercancías entre sus instalaciones. Para ello, los estudiantes desarrollaron un modelo de clasificación que predice retrasos en función de 18 factores tales como: 1) la distancia de la ruta, incluyendo la distancia real y la distancia planificada, 2) tiempo de viaje, 3) modelo de vehículo, 4) transportista, 5) ciudad de origen, 6) ciudad de destino, 7) retraso en el origen.
El análisis determinó cuáles variables eran buenos predictores y permitió a los estudiantes prever si una ruta planificada tendría baja o alta probabilidad de retraso. A continuación, los estudiantes utilizaron un árbol de decisión basado en las variables para predecir la probabilidad de retrasos en otras rutas planificadas. Sin embargo, descubrieron que el árbol de decisión era bastante sensible a los datos, por lo que cambiaron a un modelo de bosque aleatorio y evaluaron el poder explicativo y predictivo de las variables. Los factores más relevantes identificados fueron: retraso en el origen, distancia recorrida, transportista, tipo de vehículo y edad del camión. El equipo utilizó 110 árboles con una profundidad de nueve nodos, alcanzando una precisión de prueba del 73 por ciento. Se elaboró un plan de acción detallado a partir de este estudio y se implementó un monitoreo.
Machine Learning en la Gestión de Redes de Suministro
El Machine Learning (ML) presenta una vasta gama de aplicaciones en el contexto de las redes de suministro. Se puede emplear el ML en la previsión y proyección de demanda, suministro, entregas puntuales e identificación de riesgos. Esta tecnología tiene el potencial de automatizar numerosos elementos rutinarios de las operaciones de redes de suministro, además de ayudar en la detección o predicción de excepciones a la norma operativa. El ML desempeña un papel fundamental en la planificación y diseño de redes, inventarios y rutas. Además, el ML es un componente esencial en vehículos autónomos de redes de suministro, incluyendo camiones, barcos, drones de entrega y montacargas, reforzando la eficiencia y la innovación en las operaciones logísticas.
Analistas de negocio y Científicos de Datos: Una Sinergia Necesaria
Las innovaciones traídas por el Machine Learning (ML) introducen desafíos significativos relacionados con los nuevos roles y competencias necesarias, destacando una distinción clara entre los analistas de negocio tradicionales y los científicos de datos. Mientras los analistas de negocio poseen una comprensión profunda de los aspectos estratégicos y tácticos, a menudo les falta el entendimiento detallado de matemáticas avanzadas y ciencia de la computación que el equipo de ciencia de datos detiene y requiere para operar eficazmente.
Una solución innovadora para esta brecha es promover una colaboración estrecha entre analistas de negocio y científicos de datos, facilitando la recolección conjunta de datos, la realización de análisis descriptivos y la comprensión integrada de los desafíos de negocios y técnicos. Este enfoque colaborativo no solo mejora la comunicación entre los dos grupos, sino que también enriquece la toma de decisiones con insights basados en datos y análisis técnicos profundos.
Otra estrategia prometedora es la educación continua y el desarrollo de competencias, donde individuos de ambos campos son incentivados a adquirir conocimientos en los tres dominios críticos: negocios, matemáticas y ciencia de la computación. Este enfoque multidisciplinario puede crear profesionales más versátiles, capaces de navegar tanto en las complejidades del negocio como en las técnicas con mayor eficacia.
Adoptar una de estas estrategias, o idealmente una combinación de ambas, puede no solo disminuir la división entre analistas de negocio y científicos de datos, sino también potenciar la capacidad de una organización de aprovechar al máximo las oportunidades ofrecidas por el ML. La sinergia resultante puede llevar a innovaciones disruptivas, operaciones optimizadas y una ventaja competitiva sostenible en el mercado.
Aumento de Talento en la Era del Big Data
Las instituciones de educación superior enfrentan el desafío de actualizar sus currículos y herramientas pedagógicas para atender las demandas del mercado laboral actual, particularmente en el campo de las ciencias de datos. Mientras muchas universidades continúan enseñando el uso de tecnologías como Excel, que ha perdido relevancia en el mercado, hay una necesidad crítica de enfocarse en habilidades prácticas que preparen a los estudiantes para el trabajo con big data, una realidad cada vez más presente en las empresas modernas. Los proyectos académicos frecuentemente se limitan a conjuntos de datos de menor escala, no reflejando la complejidad y la escala de los datos que los profesionales encuentran en el entorno corporativo.
Para llenar esta brecha, es fundamental que los estudiantes sean entrenados para manejar grandes volúmenes de datos, utilizando una variedad de bases de datos y herramientas analíticas modernas. Además, es imperativo que los currículos aborden la importancia de la limpieza y manipulación de datos, competencias esenciales antes de siquiera considerar la modelización en Machine Learning (ML). La comprensión de que el desarrollo de modelos de ML es solo una etapa en el ciclo de vida de los datos puede ayudar a preparar profesionales más completos y versátiles.
Más allá del entorno académico, las empresas han explorado otras estrategias para desarrollar los talentos que necesitan. Los programas de entrenamiento internos surgen como una alternativa valiosa, permitiendo que las organizaciones moldeen las competencias de sus colaboradores a las necesidades específicas de sus procesos y tecnologías. Instituciones pioneras, como la FEI, han liderado el camino en la introducción de cursos innovadores en ciencia de datos, que tienen como objetivo formar profesionales con una sólida base en negocios, matemáticas y ciencia de la computación, equipándolos para enfrentar los desafíos del mercado con un enfoque multidisciplinario.
El lanzamiento de cursos dedicados a la ciencia de datos por estas universidades representa un paso importante en la dirección correcta, promoviendo una mayor integración entre la teoría académica y las prácticas del mundo real. Este tipo de iniciativa no solo beneficia a los estudiantes, preparándolos mejor para las demandas del mercado laboral, sino que también ofrece a las empresas una nueva generación de profesionales capaces de navegar con eficacia en el escenario complejo y en rápida evolución de la tecnología de la información.
Consideraciones Finales
Las máquinas y las redes de suministro están en un viaje mutuo de aprendizaje y evolución. La disponibilidad sin precedentes de datos, junto con la capacidad de entrenar modelos con millones o incluso miles de millones de datos, está redefiniendo los límites de lo posible, superando incluso la sabiduría acumulada de los más experimentados profesionales de red de suministro. Comprender las capacidades del aprendizaje automático (ML) no es solo un lujo, sino una necesidad crítica para tomar decisiones informadas sobre su aplicación efectiva.
El potencial del ML para transformar la red de suministro es vasto y aún está en gran parte inexplorado. Sin embargo, las máquinas, a pesar de su inteligencia, carecen de la percepción necesaria para identificar autónomamente los problemas más apremiantes, seleccionar los datos adecuados para el análisis o integrar soluciones de ML de manera sinérgica a los flujos de trabajo existentes. La responsabilidad de navegar por estos desafíos complejos y de liderar la integración del ML en la red de suministro recaerá en los futuros líderes del sector.
Estos líderes tendrán una doble tarea: deben poseer una comprensión profunda de las posibilidades ofrecidas por la tecnología, tanto desde el punto de vista técnico como organizacional, y tener la visión para alinear estas posibilidades con estrategias rentables. Por lo tanto, el futuro de la red de suministro depende de una comprensión amplia e integrada de las capacidades de las máquinas y las dinámicas humanas, promoviendo una colaboración eficaz entre ambas. Solo así podremos desbloquear el verdadero potencial de nuestras redes de suministro, haciéndolas más adaptables, eficientes y resilientes.